What Key is 'Hey Joe' in?
Complex Systems and Computational Methods in Interdisciplinary Research
Disclaimer: I know this is a bit of a controversial subject in the music community, so please don't take this post as the only possible truth, but take it more as informational and have fun reading it.
During my postdoctoral years at Penn, I developed a Julia package with the functions to compute the Spiral Representation and Center of Effect that Elaine Chew developed in her research and presented in her book Mathematical and Computational Modeling of Tonality. The goal for this package -besides from making the functions available to more people- was to use the representation to identify and quantify musical features such as local key (or immediate tonal center) or key transitions and study their change over time (400 years of western classical music).
The main application of the Spiral Representation is to find the tonality (key or tonal center) of a given set of notes. This is achieved by combining different concepts from music, mathematics and physics.
As an amateur cellist and with an obsessive curiosity around music, one of my favorite musicians/youtubers happens to be Adam Neely, he made a video a while ago where he makes a very detailed harmony analysis of the song "Hey Joe" by Jimi Hendrix to explain why he thinks the tonality or key of the song is E:

His video was so exciting and inspiring that I decided to test the variation of Elaine Chew's algorithm that I developed to try to answer in a more quantitative way the question:
In what key "Hey Joe" is in?
but first...
Let's introduce some definitions
Spiral Representation
The Spiral Representation (or spiral array) is a mathematical model for tonality. A geometric model that represents elements of the tonal system underlying the music with wich we are familiar, since it was constructed with harmony theory of western music.
Inspired by the helican configuration of Longuet-Higgins' harmonic network, also known as the tonnetz network shown in the next image:
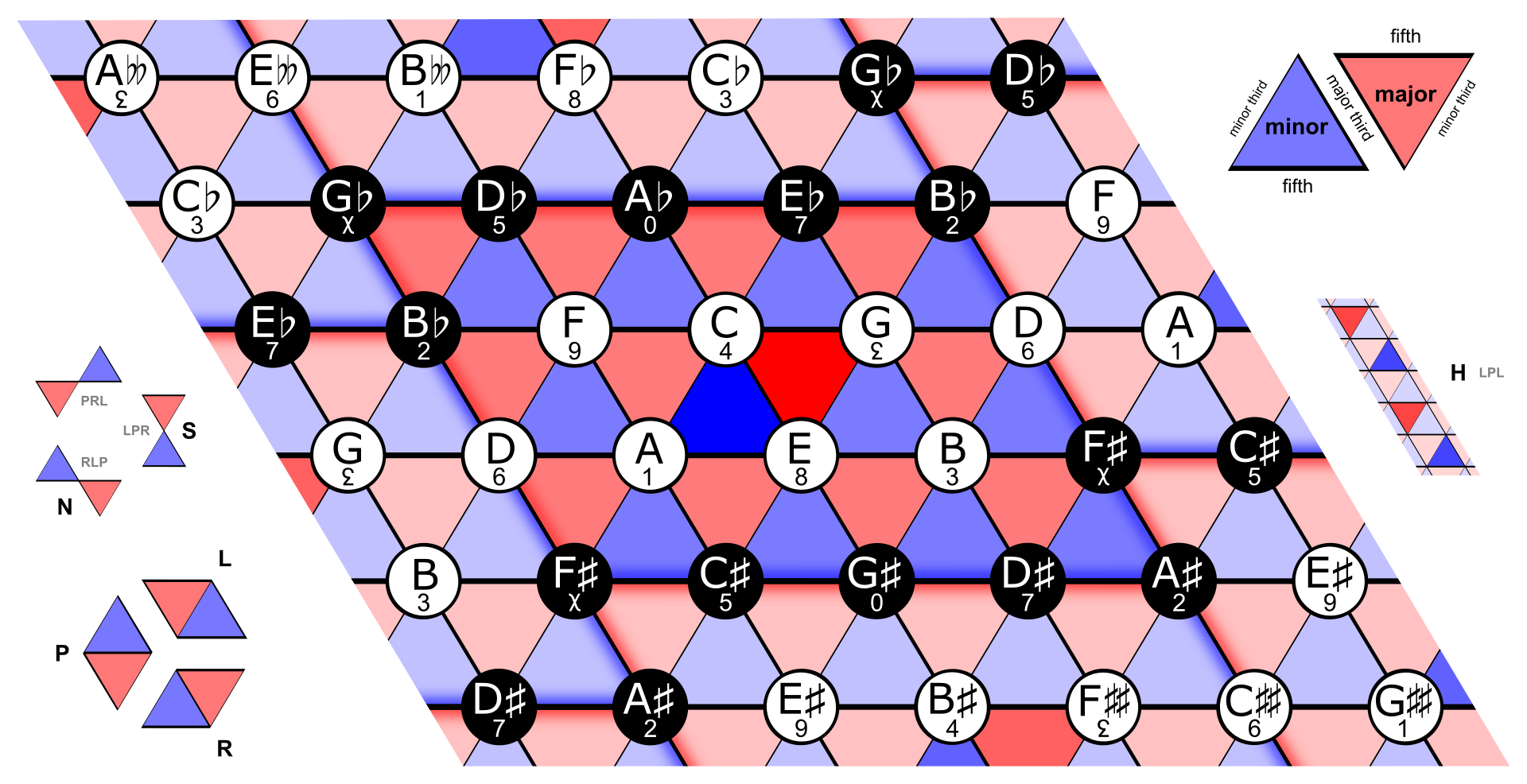
Rendering of the Tonnetz. The A minor triad is in dark blue, and the C major triad is in dark red. Interpreted as a torus, the Tonnetz has 12 nodes (pitches) and 24 triangles (triads). Image and caption from Wikipedia.

Schematic representation of pitches and their harmonic relationships in the spiral array. Figures were extracted from Elaine Chew's book: Mathematical and Computational Modeling of Tonality
The tesselation from the Tonnetz model can be illustrated in a better way if we show the planes where the major and minor chords exist:

Schematic representation of chords and keys in the spiral array. Figures were extracted from Elaine Chew's book: Mathematical and Computational Modeling of Tonality
where and are fixed: and . And is a number representing a specific note. The starting note is chosen arbitrary, for simplicity we define as the C note (e.g. with C, G, D and so on).
The major and minor chords are constructed as linear combinations of pitches:
and
where and are the tonic, major third and minor third respectively in the spiral representation. In the same fashion, the major key representations are defined from the major chords:
where and are the dominant and the subdominant chords, the minor key representations are given by:
this definition require two extra parameters to weight the different scale patterns that are presented in minor keys (natural, harmonic minor and melodic minor) given by the major and minor dominant and subdominant chords, the parameters and are set equally:
Each weighting vector in the pitch, chord and keys definitions follow and , to consider some notes (or chords) more important than the others (e.g. the tonic in a chord would be more important than the fifth and both more important than the third). For convenience, all these vectors are given equal values:
making a total of parameters for the model. Parameters were chosen from Appendix A (model calibration) of the book Mathematical and Computational Modeling of Tonality, where the author uses an heuristic approach explained in great detail.
In Machine Learning terminology, the Spiral Array can be seen as an embedding for musical notes, chords and keys in where the distances between them (their semantic relationships) are related to their harmonic relationships.
To start using code in this post I'm going to load some libraries first
#loading libraries
using CSV
using DataFrames
using Distances
using LinearAlgebra
using Random
using StatisticsJulia package for the Spiral Representation: MusicSpiralRepresentation.jl
Installation can be done via repl with the package manager
\pkg> add https://github.com/spiralizing/MusicSpiralRepresentation.jlnotice that since the package is not registered yet it should be installed using the full github address, now we can import and alias
#importing package and creating an alias
import MusicSpiralRepresentation
const msr = MusicSpiralRepresentationTo visualize the representation, we can use the Plots package and write a function to plot the pitches, chords and keys.
Loading plots and utils
using Plots
#defining a function to extract the coordinates in a format that is easier to plot
function get_xyz_loc(fs)
#concatenate the arrays n x (x,y,z)
fs_all = hcat(fs...)
#return three vectors each of them representing one variable (x,y,z)
fs_x = fs_all[1,:]
fs_y = fs_all[2,:]
fs_z = fs_all[3,:]
return fs_x, fs_y, fs_z
endNow we can plot our pitches, chords and keys (p,c,k), but first for better visualization, let's make a line for each of the path that represents each component (p,c,k):
#defining a range for our independent variable
ks = 0:0.001:11
#mapping the range to the spiral representation
#for pitches, chords and keys
fs = map(x -> msr.get_pitch(x), ks)
fsmaj = map(x -> msr.get_Major_chord(x), ks)
fsmin = map(x -> msr.get_minor_chord(x), ks)
fsmak = map(x -> msr.get_Major_key(x), ks)
fsmik = map(x -> msr.get_minor_key(x), ks)
fs_x, fs_y, fs_z = get_xyz_loc(fs)
line_maj = get_xyz_loc(fsmaj)
line_min = get_xyz_loc(fsmin)
line_mak = get_xyz_loc(fsmak)
line_mik = get_xyz_loc(fsmik);Pitches, chords and keys are already in the package with the parameters:
#getting the coordinates for each in format (x,y,z)
p_pitches = get_xyz_loc(msr.pitches[1:12])
maj_chords = get_xyz_loc(msr.major_chords[1:12])
min_chords = get_xyz_loc(msr.minor_chords[1:12])
maj_keys = get_xyz_loc(msr.major_keys[1:12])
min_keys = get_xyz_loc(msr.minor_keys[1:12]);And now we can plot the pitches, chords and keys in the Spiral Representation
pyplot(guidefont=20, titlefont=30, xtickfont=12, ytickfont=12, ztickfont=12, legendfont=12)
plot(fs_x, fs_y, fs_z, label="", linewdith=20, color=:blue, background_color=RGBA(1, 1, 1, 0),
camera=(60, 30), linestyle=:dash, zmirror=true, xlabel="X", ylabel="Y", zlabel="Z")
scatter!(p_pitches[1], p_pitches[2], p_pitches[3], size=(800, 900), m=:o, color=:blue, ms=9, label="Pitches")
plot!(line_maj[1], line_maj[2], line_maj[3], label="", linewdith=20, color=:red, linestyle=:dot)
scatter!(maj_chords[1], maj_chords[2], maj_chords[3], m=:square, color=:red, ms=9, label="Major Chords")
plot!(line_min[1], line_min[2], line_min[3], label="", linewdith=20, color=:purple, linestyle=:dot)
scatter!(min_chords[1], min_chords[2], min_chords[3], m=:diamond, color=:purple, ms=9, label="Minor Chords")
plot!(line_mak[1], line_mak[2], line_mak[3], label="", linewdith=20, color=:green)
scatter!(maj_keys[1], maj_keys[2], maj_keys[3], m=:utriangle, color=:green, ms=9, label="Major Keys")
plot!(line_mik[1], line_mik[2], line_mik[3], label="", linewdith=20, color=:orange)
scatter!(min_keys[1], min_keys[2], min_keys[3], m=:star, color=:orange, ms=12, label="Minor Keys")
How do we compute the most likely key?
The Center of Effect algorithm
The center of effect is an algorithm developed to find the most likely tonality (key) for a given set of notes in the spiral array, . This algorithm uses the concept of center of mass to represent the notes with an effective tonal center in the form of a linear combination of the positions of the notes in the spiral array:
where the weights represent the importance of the note and to mantain the values within the same boundaries the weights are normalized .
Weights can be built however we want, but one of the most natural musical features we can use for the weights is the duration of each note, under de assumption that notes that last longer are more relevant for the tonal center.
After computing the center of effect , this is compared to all the keys in the spiral representation and the closest key is selected as the most likely key.
In summary, the Center of Effect (CoE) key finding algorithm uses the vector for the set of notes, and defines the most likely key as:
which corresponds to the key for which the euclidean distance to is minimum. Here is the set of possible major and minor keys:
To exemplify how it works, let's do one of the simplest tests:
What key are the C major and c minor chords in?
The MusicSpiralRepresentation.jl package uses the same numerical notation that MIDI uses.
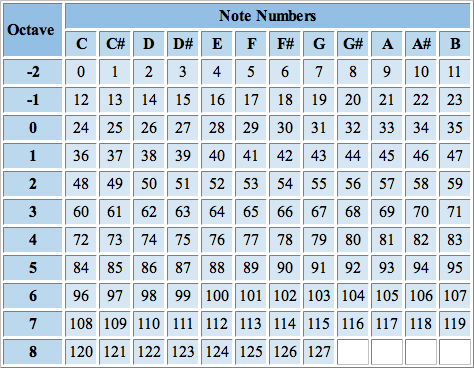
MIDI note numbers assigned to each note. Figure extracted from: https://djip.co/blog/logic-studio-9-midi-note-numbers
# array of notes in MIDI notation
c_major = [60, 64, 67] # C major chord
c_minor = [60, 63, 67] # c minor chord3-element Vector{Int64}:
60
63
67and then, we can compute the center of effect with the function get_center_effect(), this function can accept a sigle array of numbers representing the notes in MIDI notation or two arrays of numbers representing the notes in MIDI notation and their respective durations. Duration scale is irrelevant since the algorithm involves a normalization at the moment of computing .
We can see that each center of effect is different, for C major:
#first C major
msr.get_center_effect(c_major)3-element Vector{Float64}:
0.33333333333333226
0.6666666666666665
9.372141539532842and now for C minor:
msr.get_center_effect(c_minor)3-element Vector{Float64}:
0.6666666666666661
0.3333333333333331
8.520128672302583To know in what key the two sets of notes are, we need to compute the distances from the center of effect to each of the different keys in the Spiral Representation.
We can do this by calling the function get_distance_to_keys(), the function takes as argument the vector (x,y,z) for the center of effect and returns a Matrix{Any} with the keys ordered by their respective distances.
So we know what we expect if we call this function for the center of effect of our variable c_major:
msr.get_distance_to_keys(msr.get_center_effect(c_major))[1:5,:]5×2 Matrix{Any}:
"C" 0.3824
"c" 0.6841
"a" 0.8804
"G" 0.8905
"e" 0.9779and for c_minor:
msr.get_distance_to_keys(msr.get_center_effect(c_minor))[1:5,:]5×2 Matrix{Any}:
"c" 0.4517
"Eb" 0.7617
"C" 0.7977
"Ab" 0.9306
"f" 0.9481I made this computation to be the same for notes in any octave: only using a 12-note musical notation, so in principle if we do a translation by a multiple of octaves (12 semi-tones) the center of mass will be in the same position regardless of the octave of its notes.
We can test this if we move some of the notes in the C major chord by a multiple of an octave:
# making a -12 move in x and a +2*12 move in y
cmajor_2 = [60-12, 64, 67+24]
#computing the distance to keys
msr.get_distance_to_keys(msr.get_center_effect(cmajor_2))[1:5, :]5×2 Matrix{Any}:
"C" 0.3824
"c" 0.6841
"a" 0.8804
"G" 0.8905
"e" 0.9779and we obtain the same values as if we compute the distance to keys from the original center (no translation).
Now let's add some weights to those notes, since weights don't really need to be normalized as input we can use any values:
w_1 = [3,2,1]
w_2 = [1,10,1]
keys_w1 = msr.get_distance_to_keys(msr.get_center_effect(c_major, w_1))[1:5, :]
keys_w2 = msr.get_distance_to_keys(msr.get_center_effect(c_major, w_2))[1:5, :]
print("List of closest keys for $c_major with $w_1 weights: \n")
print("$keys_w1 \n \n")
print("List of closest keys for $c_major with $w_2 weights: \n")
print("$keys_w2 \n")List of closest keys for [60, 64, 67] with [3, 2, 1] weights:
Any["C" 0.4893; "c" 0.7648; "a" 0.8998; "F" 0.9642; "G" 1.0839]
List of closest keys for [60, 64, 67] with [1, 10, 1] weights:
Any["a" 0.7027; "e" 0.7294; "E" 0.8394; "A" 0.8775; "C" 1.0115]Interestingly, the set of weights w_2 adds enough emphasis on the E pitch to make the resultant closer to A minor than C major. This result does make sense because the note E is a perfect fifth away from A and makes it the dominant key for A major and minor. This is true in this case when we are giving more importance to the second note by a factor of 10.
Now let's try the algorithm with a real example, in the figure below are the first five measures of the sonata no. 16 (not 15, I am not sure why the edition of this piece on IMSLP had this number) in C major by Mozart. I made some annotations on each measure indicating what -my training in music theory tells me- key measure is in. In some of the measures I wrote down two possible keys since it is not clear to me which of the two keys is more likely.

The figure shows the first five measures from piano sonata K. 545 in C by W. A. Mozart, along with the most likely key (or two most likely keys)
Instead of input the whole piece note by note, we can use one of the formats supported by the package MusicSpiralRepresentation.jl. The package has functions to process files of two different formats: CSV and MusicXML. The CSV files can be obtained by converting MIDI files into CSV files with the software midicsv available for free online.
For this particular piece I was lucky enough to find a Music XML file in MuseScore, a music notation software that uses the MusicXML as one of their main formats in their music collection.
To load and process the MusicXML file the package uses functions from Music21 a python toolkit for computer-aided musicology, one of the advantages of Julia is that it has support to import functions from other programming languages like Python. To be able to do this we use the PyCall package that allows us to call Python functions from our Python installation, this means we need to have the module Music21 installed in the environment we are using with Julia.
Note: I still need to work on a solution to include MIDI.jl in the package for MIDI files manipulation.
# Importing PyCall and loading the module music21 as m21.
using PyCall
m21 = pyimport("music21")PyObject <module 'music21' from '/home/alfredo/.local/lib/python3.10/site-packages/music21/__init__.py'>And now we can load the music score obtained from MuseScore, using the parser/converter that is included in music21:
mozart_16 = m21.converter.parse("files/Mozart_16.mxl")PyObject <music21.stream.Score 0x7ff487b2cd90>The function m21.converter.parse() returns an object that contains all the information from the music score. To represent the music score in a more convenient way we can use the function get_xml_df() that takes the m21 object as input and returns a Data Frame with the information we need to compute the most likely keys on each measure:
| measure| Time signature|start | end | duration | pitch|
#creating a DataFrame for the music piece
df_mozart16 = msr.get_xml_df(mozart_16)1375×6 DataFrame
Row │ Measure TimeSignature StartQuarter EndQuarter Duration Pitch
│ Int64 Any Any Any Any Int64
──────┼───────────────────────────────────────────────────────────────────
1 │ 1 4/4 0.0 2.0 2.0 72
2 │ 1 4/4 2.0 3.0 1.0 76
3 │ 1 4/4 3.0 4.0 1.0 79
4 │ 1 4/4 0.0 0.5 0.5 60
5 │ 1 4/4 0.5 1.0 0.5 67
6 │ 1 4/4 1.0 1.5 0.5 64
7 │ 1 4/4 1.5 2.0 0.5 67
8 │ 1 4/4 2.0 2.5 0.5 60
⋮ │ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮And we can divide the piece by measure:
mozart16_measures = groupby(df_mozart16, :Measure);
#showing first measure
mozart16_measures[1]11×6 SubDataFrame
Row │ Measure TimeSignature StartQuarter EndQuarter Duration Pitch
│ Int64 Any Any Any Any Int64
─────┼───────────────────────────────────────────────────────────────────
1 │ 1 4/4 0.0 2.0 2.0 72
2 │ 1 4/4 2.0 3.0 1.0 76
3 │ 1 4/4 3.0 4.0 1.0 79
4 │ 1 4/4 0.0 0.5 0.5 60
5 │ 1 4/4 0.5 1.0 0.5 67
6 │ 1 4/4 1.0 1.5 0.5 64
7 │ 1 4/4 1.5 2.0 0.5 67
8 │ 1 4/4 2.0 2.5 0.5 60
9 │ 1 4/4 2.5 3.0 0.5 67
10 │ 1 4/4 3.0 3.5 0.5 64
11 │ 1 4/4 3.5 4.0 0.5 67The function get_center_effect() can also take a Matrix with this information as argument, so we just need to convert it to Matrix first and call the function, doing that with the first measure we get
msr.get_distance_to_keys(msr.get_center_effect(Matrix(mozart16_measures[1])))[1:3, :]3×2 Matrix{Any}:
"C" 0.3221
"c" 0.5756
"G" 0.876Result that agrees with the annotation for the first measure of the piece, we do this for all the other measures and inspect the first five to check which one is the most likely key for each:
#defining a function to extract only the three closest keys
function get_closest_keys(measure)
return msr.get_distance_to_keys(msr.get_center_effect(Matrix(measure)))[1:3,:]
end
#computing the closest keys for each of the measures
closest_keys = [get_closest_keys(mozart16_measures[i]) for i =1:length(mozart16_measures)];We inspect the results for the first five measures, remembering the annotations: "C", "G/C", "F/C", "G/C","F".
#printing the first 5 measures
for i = 1:5
print("The closest keys for measure $i are \n")
print("$(closest_keys[i]) \n \n")
endThe closest keys for measure 1 are
Any["C" 0.3221; "c" 0.5756; "G" 0.876]
The closest keys for measure 2 are
Any["C" 0.3622; "G" 0.4436; "g" 0.6086]
The closest keys for measure 3 are
Any["C" 0.4307; "F" 0.5666; "a" 0.5777]
The closest keys for measure 4 are
Any["C" 0.2967; "G" 0.4668; "c" 0.5786]
The closest keys for measure 5 are
Any["F" 0.2962; "C" 0.5891; "d" 0.6592]which is in agreement with the annotations. The algorithm doesn't only guess the closest key, it lists all the keys with their respective distances to the center of effect, this information can be useful to know what other keys can be considered and how close those keys are. Inspecting the second most likely keys from the algorithm we can confirm that they also agree with the annotations (for measures 2,3 and 4).
Finally, we can try to answer the question we initally made:
In what key is "Hey Joe" by Jimi Hendrix?
The approach we are going to take (there can be other alternatives) to decide in what key the song "Hey Joe" is in, is to call the closest key for each measure and then define the global key of the song as the most repeated one, in other words, the key where the center of effect spent the largest amount of time (where time units are defined as measures) in the song.
Disclaimer: the MIDI file used for this example is not guaranteed to be 100% correct, but I am trusting the source of this one.
I happen to found a MIDI file for this track on freemidi.org, to download the same file you can find it here.
Once downloaded we can convert it to CSV with:
$ midicsv HeyJoe.mid > HeyJoe.csvand we can load the file using DelimitedFiles
using DelimitedFiles
#loading the csv file with delimitedfiles
heyjoe_csv = readdlm("files/HeyJoe.csv",',')
#building the dataframe for the song
df_heyjoe = msr.get_csv_df(heyjoe_csv)
#grouping by measure
heyjoe_measures = groupby(df_heyjoe, :Measure);calculate the closest key on each measure
#writing a function that retunrs only the most likely key
function get_closest_key(measure)
#returns only the first key 1,1
return msr.get_distance_to_keys(msr.get_center_effect(Matrix(measure)))[1,1]
end
#computing the closest key for each of the measures
heyjoe_keys = [get_closest_key(heyjoe_measures[i]) for i = 1:length(heyjoe_measures)];And finally we can count the keys to get the most repeated one. To do this we can use the function get_rank_freq() that receives a sequence (an array) as input and counts how many times each of the unique elements appears in the full sequence, returning an ordered list where the first element is the most repeated one (first rank - highest frequency).
msr.get_rank_freq(heyjoe_keys)7×2 Matrix{Any}:
"E" 21
"D" 18
"e" 16
"C" 13
"G" 5
"B/Cb" 1
"b" 1With this result, there is nothing else to say but what we already heard by Adam Neely's own words...
It's in E.
If you liked this, please don't forget to take a look at the jupyter notebok with the original code here.